Machine learning (ML) is one of the most useful parts of modern AI because it turns examples into predictions. If you have historical data (emails, transactions, photos, sensor readings), ML can learn patterns and help you automate decisions at scale.
This guide explains the fundamentals in plain English and focuses on what beginners actually need: the workflow, the vocabulary, how evaluation works, and what usually goes wrong (overfitting, leakage, bad labels, and deployment surprises).
Quick mental model
Machine learning is “finding a rule from examples.” You do not write the rule yourself. The algorithm fits a model that maps inputs (features) to outputs (labels) and should generalise to new data.
1. What is machine learning?
Machine learning is a way to build software that improves through data instead of manual rule-writing. You provide examples, the model learns patterns, and then it predicts for new inputs.
Common ML questions look like:
- Is this email spam? (yes/no classification)
- What price will this house sell for? (regression: a number)
- Which customers are likely to cancel? (risk score)
- Which products should we recommend? (ranking)
Real-life example
A spam filter is not a list of “bad words.” Modern filters learn patterns from labeled emails: spam vs not spam. As tactics change, retraining with newer examples helps the model stay effective.
2. AI vs ML vs deep learning (plain English)
- AI (Artificial Intelligence): the broad umbrella for machines performing tasks that feel “intelligent”.
- ML (Machine Learning): a subset of AI where systems learn patterns from data.
- Deep learning: a subset of ML using deep neural networks (often strong for images, audio, language).
Many beginner projects do not require deep learning. If your data is tabular (spreadsheets), classic ML models can be a better starting point: simpler, faster to train, easier to debug.
3. Core concepts: dataset, features, labels, model
- Dataset: a collection of examples (rows). Each row is one case (email, customer, transaction).
- Features: inputs used to make a prediction (columns), e.g., size, location, device type, text length.
- Label / target: the “correct answer” you want the model to learn, e.g., spam/not spam, price, churn.
- Training: fitting the model to data so it learns patterns.
- Inference: using the trained model to predict on new data.
Most ML problems are data problems
If labels are inconsistent, missing, or reflect the wrong objective, the model will learn the wrong thing. Before changing algorithms, validate labeling rules and data quality.
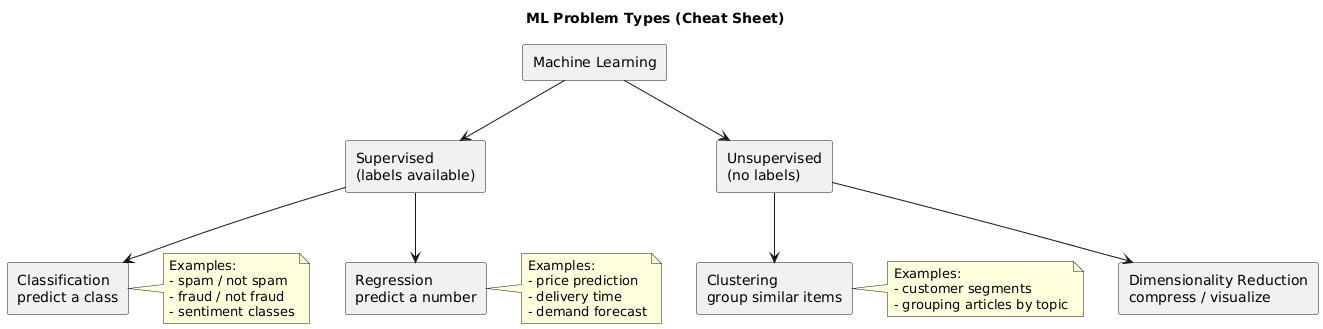
4. Problem types: classification, regression, clustering
Most ML tasks fall into a small number of categories:
Classification
Predict a category (spam/not spam, fraud/not fraud, sentiment classes).
Regression
Predict a number (price, demand, time-to-delivery).
Clustering (unsupervised)
Group similar items without labels (customer segments, article topics).
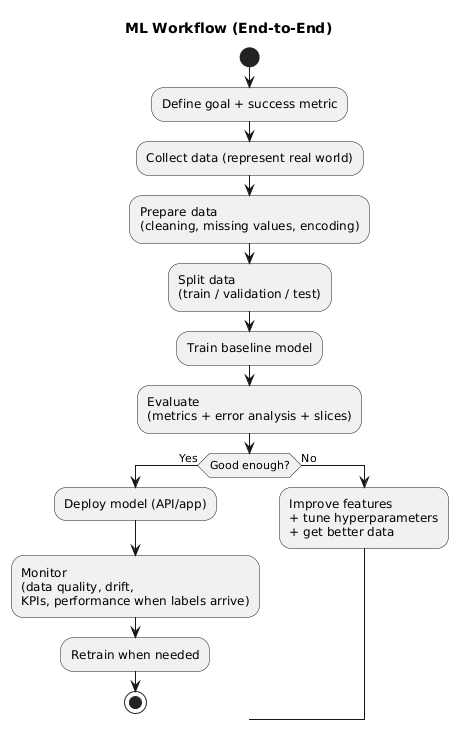
5. The ML workflow (end to end)
Real ML is a repeatable process, not just “train a model.” A practical workflow:
- Define the goal: what decision will the model support, and what is success?
- Collect data: examples that represent the real world you care about.
- Prepare: clean data, handle missing values, standardise formats.
- Split: train/validation/test (or time-based splits for time series).
- Baseline: train a simple model to establish a reference.
- Iterate: improve features, tune hyperparameters, compare models.
- Evaluate: metrics + error analysis (where does it fail?) + slice checks.
- Deploy: integrate into your app/service.
- Monitor: data quality, drift, performance, and business KPIs.
- Retrain: refresh when the world changes.
6. Train/validation/test and cross-validation
Splitting is how you measure generalisation: whether the model works on data it has not seen. A common setup:
- Train set: used to fit the model.
- Validation set: used to tune choices (features, hyperparameters).
- Test set: final “unseen” evaluation used only at the end.
For small datasets, cross-validation gives more stable estimates by training multiple times on different folds.
Time-series and “future” data
If your data is time-ordered (forecasting, churn over time), avoid random splits that leak future information. Use time-based splits to mimic real production.
7. Feature engineering (what matters most)
Feature engineering is the craft of turning raw input into useful signals. In practice, better features often beat a more complex algorithm. Examples:
- Dates: day of week, month, time since last action.
- Text: length, presence of keywords, TF-IDF vectors, embeddings (for advanced setups).
- Categoricals: one-hot encoding, frequency encoding, “other/unknown” bucket.
- Aggregations: rolling averages, counts per user, recent activity windows.
Practical habit
Write down the “obvious” rules a human would use. Many of those become great engineered features.
8. Common beginner models (and when to use them)
| Model | Best for | Why beginners like it | Typical downside |
|---|---|---|---|
| Linear regression | Regression baseline | Fast, interpretable | Misses non-linear patterns |
| Logistic regression | Classification baseline | Strong baseline, calibrated probabilities | May underfit complex boundaries |
| Decision tree | Quick, explainable models | Readable rules | Often overfits without tuning |
| Random forest | General tabular problems | Good defaults, robust | Less interpretable, heavier inference |
| Gradient boosting | High performance on tabular | Often top-tier results | More tuning, can overfit |
9. Evaluation metrics (classification + regression)
Classification metrics
- Accuracy: overall correctness (can be misleading with imbalanced classes).
- Precision: when predicting positive, how often correct (controls false positives).
- Recall: how many true positives you caught (controls false negatives).
- F1 score: balances precision and recall.
- Confusion matrix: makes error types obvious.
Why accuracy can lie
If only 1% of transactions are fraud, always predicting “not fraud” yields 99% accuracy—but catches zero fraud. In that setting, precision/recall (and PR-AUC) are more informative.
Regression metrics
- MAE: average absolute error (easy to interpret).
- RMSE: penalises larger errors more strongly.
- R²: explains variance (use carefully; can mislead with leakage).
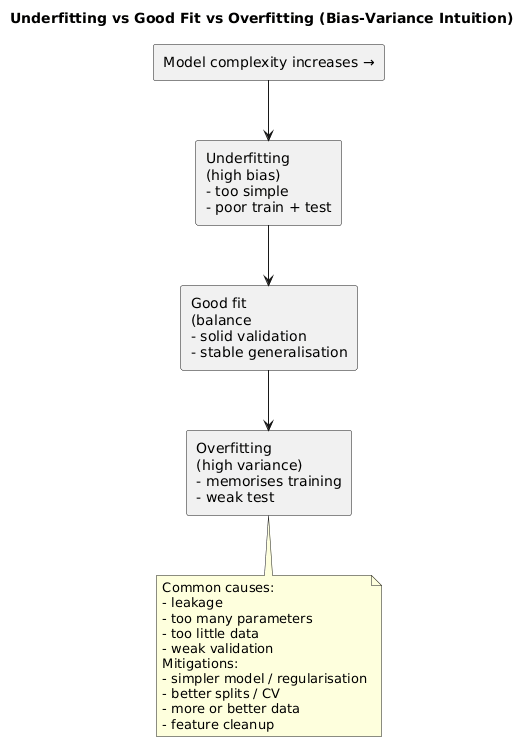
10. Overfitting, underfitting, and data leakage
These three concepts explain a large share of “works in training, fails in real life” stories.
Overfitting
The model memorises training data instead of learning general patterns. Training score is high, test score is low. Causes: too complex model, too many iterations, weak validation, leakage.
Underfitting
The model is too simple or features are too weak. Performance is poor even on training data.
Data leakage (the silent killer)
Leakage happens when features include information that would not exist at prediction time (or indirectly encode the answer). It creates unrealistically good evaluation that collapses in production.
11. From notebook to production: deployment + monitoring basics
If you ever ship ML, the model is only one part of the system. You also need:
- Versioning: model version, data version, feature logic version.
- Inference contract: inputs and outputs well-defined (schemas).
- Monitoring: input data quality, drift, performance (when labels exist), and business KPIs.
- Rollback plan: ability to revert to a known-good model quickly.
Beginner-friendly production rule
Start by monitoring simple things: null spikes, category explosions, prediction distribution changes, and a small sample of manual reviews. This catches many issues early.
12. Beginner projects (with clear success criteria)
Projects are how ML “clicks.” Pick datasets you can explain to another person and define success up front.
Project 1: classification
- Goal: predict a label (e.g., sentiment, spam, churn).
- Success metric: precision/recall or F1 (not only accuracy).
- Deliverable: confusion matrix + short error analysis (“where does it fail and why?”).
Project 2: regression
- Goal: predict a number (prices, durations, demand).
- Success metric: MAE/RMSE vs a baseline.
- Deliverable: plot predicted vs actual + top error cases.
Project 3: clustering
- Goal: segment items/users.
- Success metric: interpretability and usefulness (clusters you can describe in words).
- Deliverable: cluster profiles + examples from each cluster.
13. A realistic beginner learning path
- Step 1: learn the vocabulary and the workflow (features, labels, splitting, metrics).
- Step 2: learn one library well (often scikit-learn) and practice pipelines.
- Step 3: build the three projects above.
- Step 4: improve one project: features, evaluation, and a short “model report”.
- Step 5: learn basic deployment concepts: input schemas, monitoring, rollback.
For more resources, browse the Artificial Intelligence guides section.
14. Frequently Asked Questions
What is the difference between AI and machine learning?
AI is the broad umbrella. Machine learning is a subset of AI where systems learn patterns from data instead of being programmed with every rule.
Do I need advanced math to start learning machine learning?
Not to start. You can learn the core ideas and build simple models with minimal math. More math becomes useful as you move into statistics, optimization, and deep learning.
What is supervised learning in simple terms?
Supervised learning means learning from labeled examples, like emails marked spam/not spam or photos labeled cat/dog.
What is overfitting and why is it a problem?
Overfitting happens when a model memorizes the training data instead of learning general patterns. It may look great during training but perform poorly on new, unseen data.
Is machine learning always the right solution?
Not always. If a simple rule solves the problem reliably, traditional programming is often cheaper and easier to maintain. ML is most valuable when rules are too complex to write by hand or when patterns change over time.
How do I start learning machine learning as a beginner?
Start with the workflow basics (features, labels, train/test split), learn one beginner-friendly library such as scikit-learn, and build three small projects: classification, regression, and clustering. Then improve one project with better features, evaluation, and a short model report.
Key ML terms (quick glossary)
- Dataset
- A collection of examples used to train or evaluate a model.
- Feature
- An input attribute used by a model (e.g., size, location, text length, time of day).
- Label (Target)
- The correct output you want to predict in supervised learning (e.g., spam/not spam, price).
- Model
- The learned function that maps features to predictions.
- Training
- Fitting the model to data so it learns patterns.
- Inference
- Using the trained model to produce predictions on new data.
- Train/Validation/Test split
- Separating data so you can measure generalisation and avoid tuning on the test set.
- Overfitting
- When a model performs well on training data but fails to generalise to new data.
- Data leakage
- When features contain information not available at prediction time, making evaluation look unrealistically good.
Worth reading
Recommended guides from the category.